Using maimonides’ rule to estimate the effect of class size on scholastic achievement
Author
Molly Tseng
Published
April 21, 2026
Introduction
This paper studies an important question in education:
Do smaller classes improve students’ academic performance?
Answering this question is difficult because class size is not randomly assigned. Schools with better resources or students from wealthier backgrounds may also have different class sizes, making it hard to identify causal effects.
To address this issue, the authors use a rule from Israeli schools, known as Maimonides’ rule, which sets a maximum class size of 40 students. When enrollment exceeds 40, classes are split, leading to a sudden drop in class size.
This creates a natural experiment: students in grades with 39 and 41 students are very similar, but experience very different class sizes. The authors exploit this discontinuity by using the class size predicted by the rule as an instrument for actual class size, within a regression discontinuity framework, to identify causal effects.
The results show that smaller classes significantly improve test scores for fifth graders, have a modest positive effect for fourth graders, and show little effect for third graders, likely due to data limitations.
Overall, the findings suggest that reducing class size can have meaningful benefits for student achievement, especially for older students, and highlight the importance of using credible identification strategies to estimate causal effects in education policy.
Main Analysis
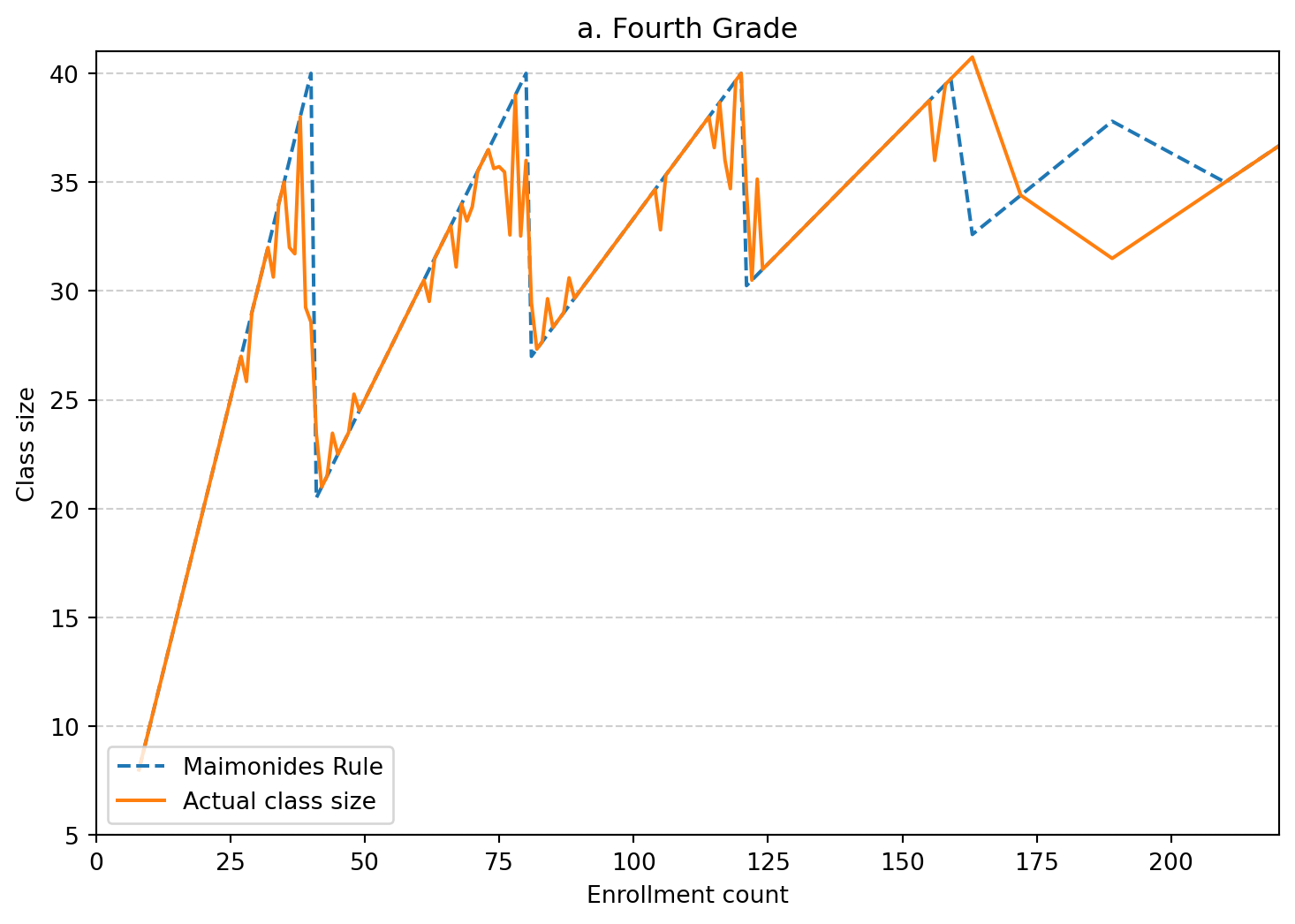
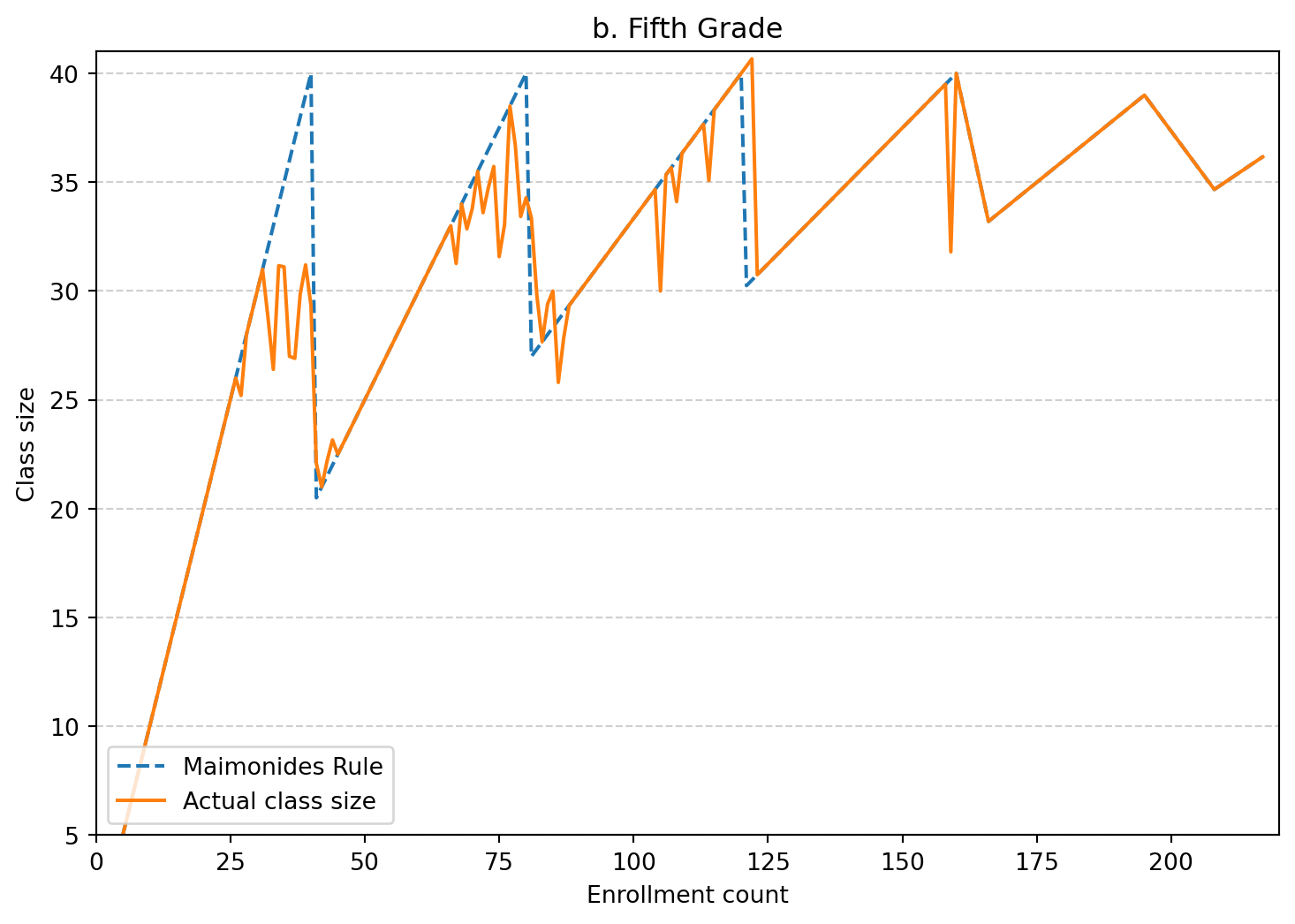
Figure 1 (4th grade) - intuition
Figure 1 shows how Maimonides’ Rule creates variation in class size based on enrollment. As enrollment increases, class size rises until it reaches 40 students. Once enrollment passes this threshold, classes are split, causing a sudden drop in average class size.
This creates a sawtooth pattern: class size increases smoothly but drops sharply at cutoffs like 40 and 80. Schools just below and above these cutoffs are very similar, except for class size.
This discontinuity provides useful variation that allows us to estimate the causal effect of class size using a regression discontinuity design.
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport statsmodels.api as smdf4 = pd.read_stata("/Users/mollytseng/Desktop/UCSD/quarto_website/posts/Angrist_Lavy_papers/data/dataverse_files/final4.dta")print(df4.columns.tolist())df4.head()# Maimonides Ruledf4["pred_class_size"] = df4["cohsize"] / (np.floor((df4["cohsize"] -1) /40) +1)# group by enrollmentfig1_data = ( df4.groupby("cohsize", as_index=False) .agg( actual_class_size=("classize", "mean"), pred_class_size=("pred_class_size", "mean") ) .sort_values("cohsize"))print(fig1_data)# plotplt.figure(figsize=(9,6))plt.plot( fig1_data["cohsize"], fig1_data["pred_class_size"], linestyle="--", label="Maimonides Rule")plt.plot( fig1_data["cohsize"], fig1_data["actual_class_size"], linestyle="-", label="Actual class size")plt.xlim(0, 220)plt.ylim(5, 41)plt.xlabel("Enrollment count")plt.ylabel("Class size")plt.title("a. Fourth Grade")plt.grid(axis="y", linestyle="--", alpha=0.6)plt.legend(loc="lower left")plt.show()
A simple OLS regression of test scores on class size is first estimated. This shows the basic relationship between class size and student achievement in the data.
However, this estimate may be biased because class size is not randomly assigned. Schools with different class sizes may also differ in student background or other factors that affect test scores. Therefore, the OLS results reflect correlation, not necessarily a causal effect.
def run_ols(data, y, x): temp = data[[y] + x].dropna() X = sm.add_constant(temp[x]) model = sm.OLS(temp[y], X).fit(cov_type="HC1")return model# Column 7ols_7 = run_ols(df4, "avgverb", ["classize"])# Column 10ols_10 = run_ols(df4, "avgmath", ["classize"])print(ols_7.summary())print(ols_10.summary())
The positive relationship is misleading. Larger classes are often found in better schools with stronger students, so higher test scores are driven by student background, not class size itself.
Table III - RDD
This step uses Maimonides’ Rule to estimate the effect of class size. Instead of relying on actual class size directly, it uses the class size predicted by the rule, which depends only on enrollment.
Because the rule creates sudden changes in class size at specific enrollment cutoffs, it provides a source of variation that is less likely to be related to student background or school quality. This makes the estimate more credible and closer to the true causal effect of class size on test scores.
Comparing the naive OLS and reduced-form estimates, the results change both in magnitude and sign. The OLS estimates suggest a positive relationship between class size and test scores, implying that larger classes are associated with better performance. However, this result is likely driven by selection bias.
In contrast, the reduced-form estimates based on Maimonides’ Rule show a negative relationship between class size and reading scores. This suggests that larger classes actually reduce student achievement once more credible variation is used.
The key difference is that the OLS estimates capture correlations influenced by student background and school characteristics, while the reduced-form approach isolates variation in class size that is driven by enrollment rules. As a result, the reduced-form estimates provide a more reliable indication of the causal effect of class size.
Something Additional
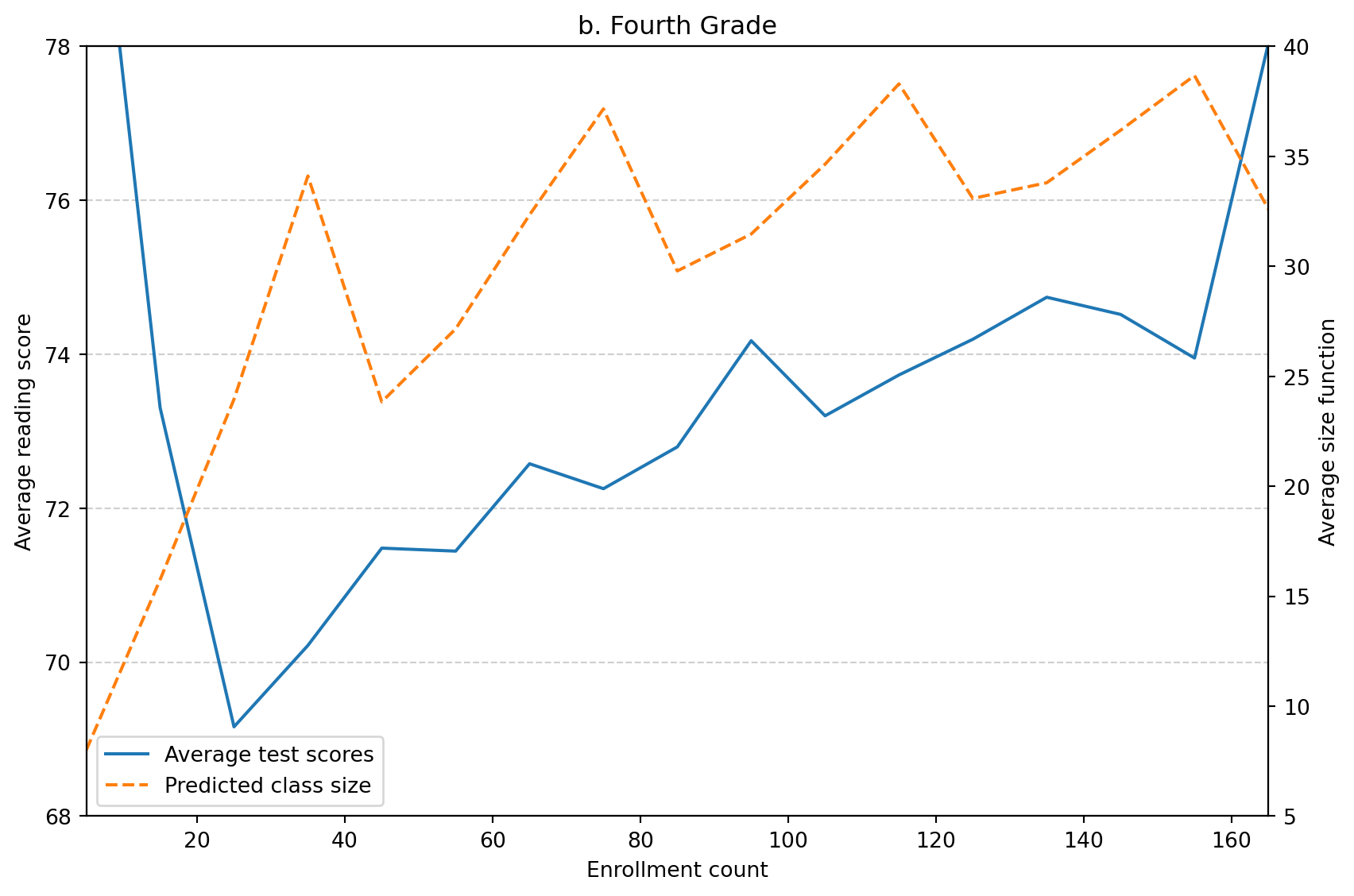
As an additional analysis, I plot average reading scores against enrollment to provide a visual complement to the regression results.
The pattern appears to move in the opposite direction of class size. When enrollment crosses thresholds such as 40 or 80, class size drops, and test scores tend to increase. This mirrors the pattern observed in Figure 1.
Using Maimonides’ Rule, this paper finds that smaller class sizes improve student achievement, particularly in reading. While naive OLS results are biased, the regression discontinuity approach provides more credible evidence of a negative causal effect of class size.